-DrawMe.png)
—— 从 StructuredBuffer 到 Instancing UBO 的架构演进
一、问题背景
在移动端项目中,需要同时渲染数百至上千个带骨骼动画的怪物角色。
目标:
极低 DrawCall
CPU 消耗接近 0
兼容 GLES / Vulkan / Metal / D3D11 等常见平台
低端 Mali 可运行
高端 Adreno 可扩展
可稳定 30fps
传统 SkinnedMeshRenderer 在实例数量增加时会迅速成为瓶颈,因此选择:
GPU Animation(骨骼动画贴图驱动)+ DrawMeshInstanced作为核心技术方案。
二、GPU Animation 基础架构
1️⃣ 动画烘焙
将每个动画 Clip 的骨骼矩阵预计算并写入纹理:
每骨骼 4 行 float4
每帧连续排列
Clip 线性存储
Shader 通过:
(animState, currentFrame, boneIndex)
计算 UV,采样得到当前骨骼矩阵。
优势:
所有实例共享动画数据
CPU 不参与骨骼计算
天然适合 Instancing
2️⃣ 实例数据
每个实例需要:
float4x4 modelMatrix
float4 animParams (state, speed, offset, etc.)
初版 Vulkan 路径使用:
StructuredBuffer<float4x4>
StructuredBuffer<float4>
StructuredBuffer<ClipInfo>
GLES 路径使用:
Instancing UBO + 常量数组
三、问题出现:Vulkan 反而更慢
在骁龙 8 Gen 3 上测试:
API 空场景 200怪
GLES 2.5ms 5.5ms
Vulkan 1.2ms 6.5ms
空场景 Vulkan 更快
加怪后 Vulkan 更慢
说明:
问题不在 API
问题在数据访问路径
四、核心差异:UBO vs SSBO
移动 GPU 上,UBO 和 SSBO 的差异远大于桌面 GPU。
桌面 GPU:
UBO ≈ SSBO
移动 GPU:
UBO >> SSBO
原因涉及移动 GPU 架构。
五、移动 GPU 架构差异(关键点)
大部分移动 GPU(Mali / Adreno)采用:Tile-Based Deferred Rendering (TBDR)
特点:
小 cache
片上 tile buffer
内存带宽极其宝贵
延迟隐藏能力有限
1️⃣ UBO 访问路径
UBO:
走专用常量缓存
广播给所有 shader lane
延迟低
适合频繁访问
2️⃣ SSBO 访问路径
StructuredBuffer:
走全局内存
需要地址计算
不一定缓存
延迟更高
多实例访问容易产生 cache miss
六、问题本质
初版 Vulkan Shader 每顶点访问:
_InstanceMatrices[instanceID]
_InstanceAnimParams[instanceID]
_AnimClips[animState]
即:
每顶点 3 次 SSBO 访问。
再加上:
每骨骼 4 次贴图采样
每顶点 4 骨骼
访问总量巨大。
在移动 GPU 上:
SSBO 成为性能放大器。
七、优化策略:数据路径重构
目标:
把 SSBO 访问次数降到 0
优化 1:Clip 数据改为常量数组
从:
StructuredBuffer<ClipInfo>
改为:
float4 _AnimClips_Float[3];
优势:
走 uniform cache
animState 读取几乎零成本
无实例差异
优化 2:Instance 数据改为 Instancing UBO
使用:
UNITY_DEFINE_INSTANCED_PROP(float4x4, _InstanceMatrix)
UNITY_DEFINE_INSTANCED_PROP(float4, _InstanceAnimParams)
替代 StructuredBuffer。
优势:
走 UBO
受 64KB 限制(但 1023 实例足够手游)
广播访问更高效
优化 3:减少重复 clip 读取
将:
_AnimClips_Float[animState]
读取一次后缓存到局部变量,
避免每骨骼重复读取。
八、优化结果
高端设备:
Vulkan 性能接近 GLES
低端 Mali:
提升更明显
性能瓶颈重新回归:贴图采样/顶点数量/Fillrate
而不是数据访问路径。
九、DrawMeshInstanced vs Procedural
在移动端:
DrawMeshInstanced
优于:
DrawMeshInstancedProcedural
原因:
Instancing UBO 优化成熟
驱动路径更稳定
不依赖 GPU 决定实例数量
Procedural 更适合:
GPU Culling
Compute 驱动渲染
Indirect Draw
不适合当前手游场景。
十、最终稳定架构
DrawMeshInstanced
Instancing UBO
Uniform Clip Array
Bone Animation Texture
RenderScale 分档
特性:
DC 极低
CPU < 0.5ms
低端 200怪稳定
高端 1000怪可扩展
无 SSBO 依赖
十一、性能认知重构
通过完整测试得到几个关键结论:
移动端瓶颈通常不是 DrawCall
SSBO 在移动 GPU 上代价远高于桌面
Fillrate 比顶点更敏感
RenderScale 是核心性能杠杆
GPU Animation 是 GPU 绑定型方案
十二、工程意义
这次优化并非“代码调优”,而是:
数据访问路径级别的架构修正。
它揭示了一个重要事实:
跨 API 优化,必须理解 GPU 硬件架构,而不是只看接口形式。
方案具体实现:
1、 用烘焙工具,生成GPUAnim资产
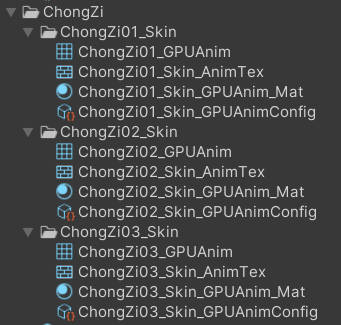
生成一个mesh,一个Tex,
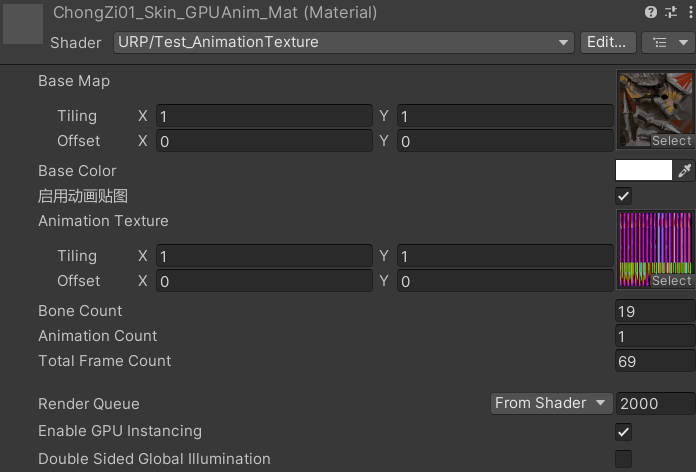
一个材质球,
一个配置文件
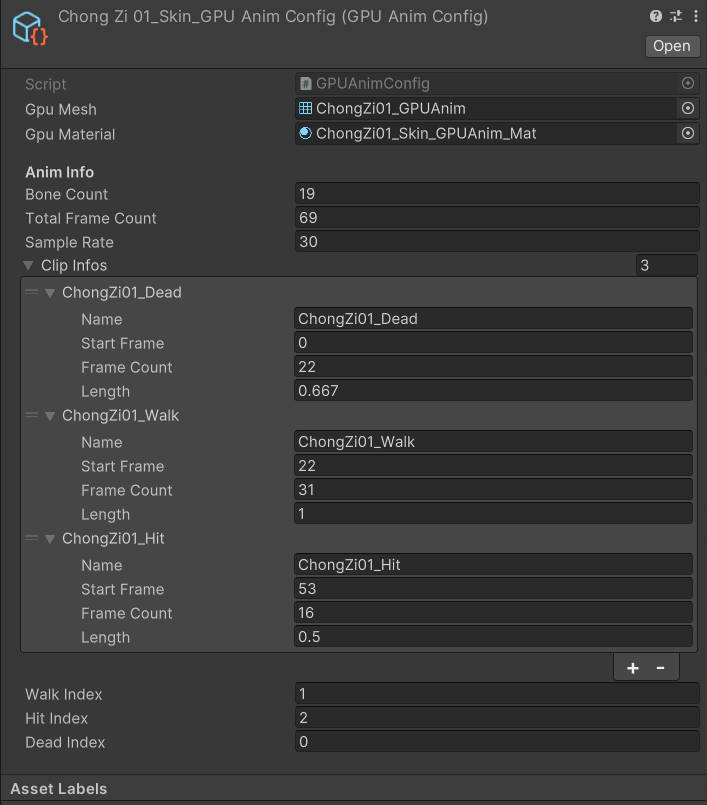
2.场景内增加一个gameobject,添加GPUAnimManger(总控)
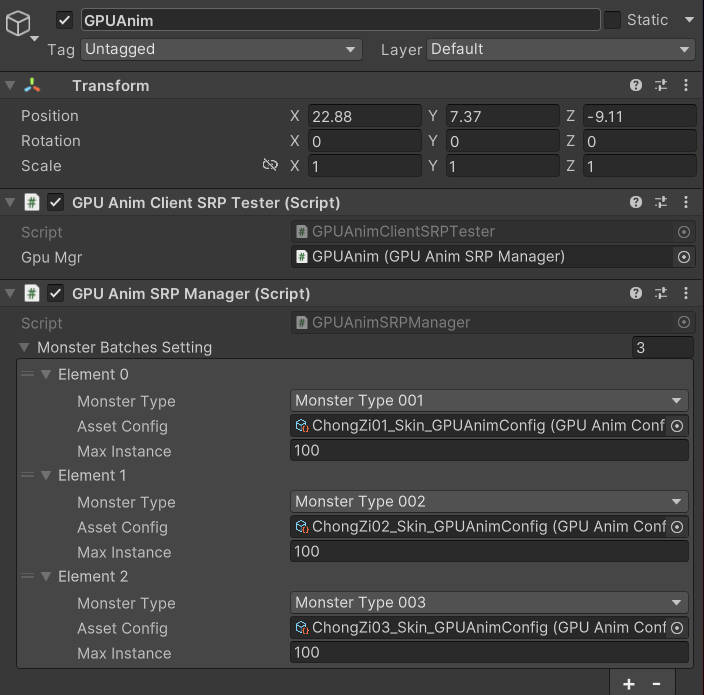
3.管线配置文件增加RenderFeature

4.客户端调用相应的方法即可控制,生成怪物,销毁怪物,动画切换等(因为是实例化,会用到索引池)
结语
从 StructuredBuffer 到 Instancing UBO 的迁移,本质不是 API 切换,而是:
从“桌面思维”到“移动 GPU 思维”的转变。
在移动端优化中:
正确的数据路径
往往比算法本身更重要。






暂无评论内容